The challenge with concurrency
Today we take a major step forward by extending our elastic architecture to solve another major pain point in existing on-premises and cloud data warehousing solutions: how to run massively concurrent workloads at scale in a single system.
Have you had the following experiences when building mission-critical applications that incorporate data analytics:
- My application can only support a certain level of user concurrency due to the underlying data warehouse, which only allows 32-50 concurrent user queries.
- To build my application, I need to acquire multiple data warehouse instances in order to isolate numerous workloads and users from each other. This adds to costs and complexity.
- We have built our own scheduling policies around the data warehouse. We use query queues to control and prioritize incoming queries issued by our numerous users.
- During peak times, users are getting frustrated because their requests are getting queued or fail entirely.
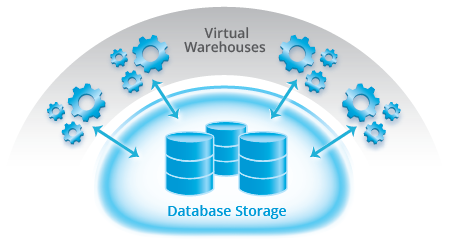
At Snowflake, we separate compute from storage by introducing the unique concept of virtual data warehouses. That concept makes it possible to instantly resize virtual warehouses or pause them entirely. In addition, because of that concept Snowflake is the only cloud data warehousing solution that allows concurrent workloads to run without impacting each other.
However, we saw the need to go a step further to offer a service that adapts to changing workloads and addresses concurrency at the same time:
- Imagine you didn’t have any concurrency limitations on your mission-critical business application.
- Imagine you didn’t need users to adjust their workloads to accommodate data warehouse bottlenecks.
- Imagine the data warehouse itself could detect increasing workloads and add additional compute resources as needed or shut-down/pause compute resources when workload activities subside again.
- Imagine your application could scale out-of-the-box with one single (virtual) data warehouse without the need to provision additional data warehouses.
- Imagine a world without any scheduling scripts and queued queries – a world in which you can leverage a smart data warehousing service that ensures all your users get their questions answered within the application’s SLA.
With Snowflake, we allow you to do that all of this for real, not just in your imagination, with our new multi-cluster data warehouse feature.
Multi-cluster data warehouses
A virtual warehouse represents a number of physical nodes a user can provision to perform data warehousing tasks, e.g. running analytical queries. While a user can instantly resize a warehouse by choosing a different size (e.g. from small to 3X large), until now a virtual data warehouse in Snowflake always consisted of one physical cluster.
With the recent introduction of multi-cluster warehouses, Snowflake supports allocating, either statically or dynamically, more resources for a warehouse by specifying additional clusters for the warehouse.
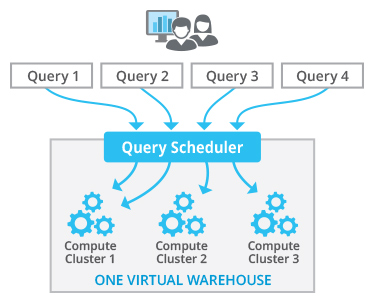
The figure above shows a multi-cluster DW that consists of three compute clusters. All compute clusters in the warehouse are of the same size. The user can choose from two different modes for the warehouse:
- Maximized: When the warehouse is started, Snowflake always starts all the clusters to ensure maximum resources are available while the warehouse is running.
- Auto Scaling: Snowflake starts and stops clusters as needed to dynamically manage the workload on the warehouse.
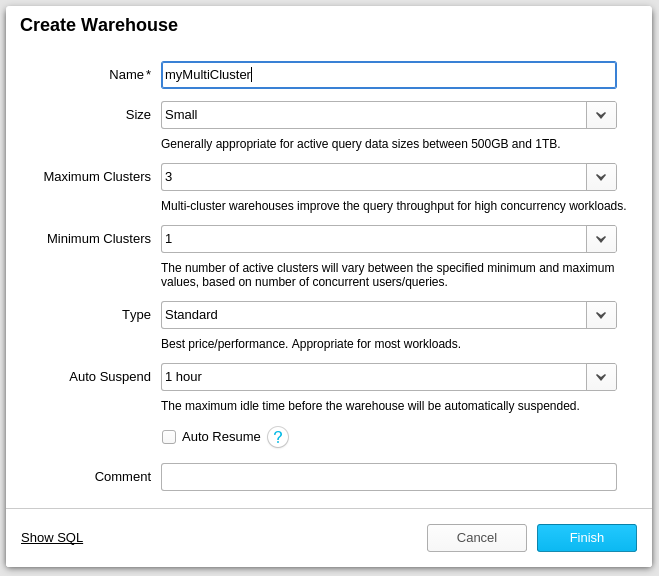
As always, in Snowflake a user can either leverage the user interface or use SQL to specify the minimum/maximum number of clusters per multi-cluster DW:
Create Warehouse UI wizard
Create Warehouse SQL script

Similar to regular virtual warehouses, a user can resize all additional clusters of a multi-cluster warehouse instantly by choosing a different size (e.g. XS, S, M, L, …) either through the UI or programmatically via corresponding SQL DDL statements. In auto-scale mode, Snowflake automatically adds or resumes additional clusters (up to the maximum number defined by user) as soon as the workload increases. If the load subsides again, Snowflake shuts down or pauses the additional clusters. No user interaction is required – this all takes place transparently to the end user.
For these decisions, internally, the query scheduler takes into account multiple factors. There are two main factors considered in this context:
- The memory capacity of the cluster, i.e. whether clusters have reached their maximum memory capacity
- The degree of concurrency in a particular cluster, i.e. whether there are many queries executing concurrently on the cluster
As we learn more from our customers’ use cases, we will extend this feature further and share interesting use cases where multi-cluster data warehouses make a difference. Please stay tuned as we continue reinventing modern data warehousing and analytics by leveraging the core principles of cloud computing.
We would like to thank our co-authors, Florian Funke and Benoit Dageville, for their significant contributions as main engineer and architect, respectively, to making multi-cluster warehouses a reality. As always, keep an eye on the blog and our Snowflake Twitter feed (@SnowflakeDB) for updates on Snowflake Computing.



