The recent MongoDB World conference in New York was a testament to the rapid growth and adoption of MongoDB among a wide array of organizations and use cases–connected home IoT, streaming video, online gaming, community forum platforms, and more.
What’s common across a lot of these use cases is lots of rapidly-growing data–log data, event data, monitoring data, and the like. MongoDB is a great fit for that because it’s able to scale to support quick access to data elements even at high concurrency levels. MongoDB can do a good job handling lots of the small or modest-sized reads of data done by applications that use it to support online data access (think lookups and simple aggregations supporting web applications, for example).
What about analytics?
Once you have a lot of data in MongoDB, the next question is of course what do you do when you want to start doing analytics on that data?
You can get started with the capabilities in the MongoDB aggregation framework (e.g. counts, averages, totals, etc.). There’s also the option to use native MapReduce processing for custom logic and you can even use the MongoDB BI Connector to provide basic support for SQL-based BI and visualization tools. That can work for modest analytics needs when it’s imperative to do basic analytic operations on the data inside the operational system.
However, that isn’t enough to meet most analytics needs.
- Doing analytics inside MongoDB starts to break down as it becomes more demanding. As data and workloads scale, heavy-duty analytics consume more and more resources, making it harder and harder to maintain performance for operational access.
- There are a lot of places where SQL is the tool for the job, not least because it’s the native language of a huge array of BI and analytics tools out there. However, the inefficiencies of translating SQL generated by BI and analytics tools into MongoDB queries slow down analytics, limiting what you can do natively in MongoDB.
- When you need to combine the type of data that typically resides in MongoDB with traditional data, you start needing not only full SQL support but also the ability to support dimensional models and handle more heavy-duty JOIN operations.
Those are just a few of the reasons that people start looking for solutions that can help them get more value out of the data that they have in MongoDB. What’s needed: a solution that doesn’t require lots of complex ETL, that can keep up with the large amount of data being generated and stored, and that can do all of that at a reasonable cost.
Snowflake for MongoDB analytics
We’re seeing more and more customers turning to Snowflake for a system that provides that. Snowflake is a great complement to MongoDB for a number of reasons.
Native support for JSON, the data structure used at the heart of MongoDB’s document-oriented model. Because Snowflake can load JSON data natively without requiring transformation to a fixed relational schema, it’s easy to get data from MongoDB into Snowflake. There’s no need to build an ETL pipeline to transform that data and no need to worry about anything breaking as the data structure evolves.
Unique architecture built for online elasticity and scale. When you’ve got lots of data arriving at highly variable but potentially rapid rates, you need a system that can easily keep up. Snowflake’s multi-cluster, shared data architecture makes it possible to load data at any time without competing for resources with analytics. That allows you to do micro-batch loading at any time to keep up with fast-arriving streams of data so that analysts have rapid access to recent data. Need to load a lot of data quickly? With Snowflake you can accelerate loading by simply scaling up a virtual warehouse—no downtime, read-only mode, or data redistribution required.
Native SQL support, even for JSON. Snowflake comes with a robust SQL engine at its core, making your BI and analytics tools hum along in the way they were designed to interact with data. Even better, Snowflake’s SQL isn’t limited to just relational data—that JSON data you have in MongoDB with its variable schema, hierarchies, and nesting? All accessible from SQL via Snowflake’s extensions and ability to create relational views on top of that data to make it friendly to SQL-based tools.
Putting the pieces together
Combining MongoDB with Snowflake allows you to bring the benefits of MongoDB in supporting live applications together with the analytics flexibility and power of the Snowflake data warehouse. MongoDB supplies live applications with fast response and simple analytics, while data is copied into Snowflake in small batches every few minutes so that it can be combined with other data for more demanding analytics supporting BI and analytics teams.
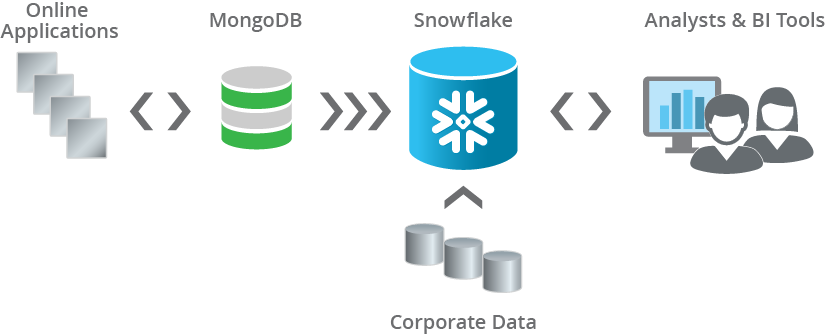
As an example, we wrote earlier about how DoubleDown Interactive was struggling with their prior data pipeline, trying to figure out how to make their online game event data available to analysts using BI and dashboarding tools. DoubleDown was able to dramatically simplify their data pipeline and get data to BI analysts faster by eliminating the transformations that they were previously trying to do in MongoDB and moving the data directly into Snowflake.
It’s all part of how people have been reinventing the solutions supporting their rapidly growing and evolving needs for analytics, a reinvention that Snowflake is helping to drive.



