
the snowflake
platform
A single, global platform that powers the Data Cloud. Snowflake is uniquely designed to connect businesses globally, across any type or scale of data and many different workloads, and unlock seamless data collaboration.

ONE PLATFORM WITH
NEAR-UNLIMITED POTENTIAL
Get the performance, flexibility, and scalability you need to load, integrate, analyze, and share your data—securely. As a fully managed service, Snowflake is easy to use, yet powerful enough to run your essential workloads with near-unlimited concurrency.
OPTIMAL PERFORMANCE
FOR ANY WORKLOAD
Never worry about resource contention again. Snowflake’s single elastic performance engine delivers instant and near-unlimited scale. Support a virtually unlimited number of concurrent users and workloads ranging from interactive to batch—all with reliable, fast performance, thanks to Snowflake’s multi-cluster resource isolation.
FULLY AUTOMATED SO YOU CAN HARNESS (NOT MANAGE) DATA
Trade in manual management and maintenance for automations that enable you to easily operate at scale, optimize costs, and minimize downtime. Snowflake’s platform is fully managed to support effortless data management, security, governance, availability, and data resiliency―reducing risk and improving your operational efficiency.
Collaborate Globally
and Securely
Say goodbye to ETL and data silos. Easily and securely access and share a single copy of your data across your departments, business units, and subsidiaries; with your supply chain and other business ecosystem partners; and with thousands of organizations that make up the Data Cloud. Seamlessly connect cross-cloud and cross-region and enable global governance policies that follow the data.
Flexible Architecture
NO DATA SILOS
Snowflake’s unique architectural design connects your business across clouds, globally, and at any scale to mobilize your data.
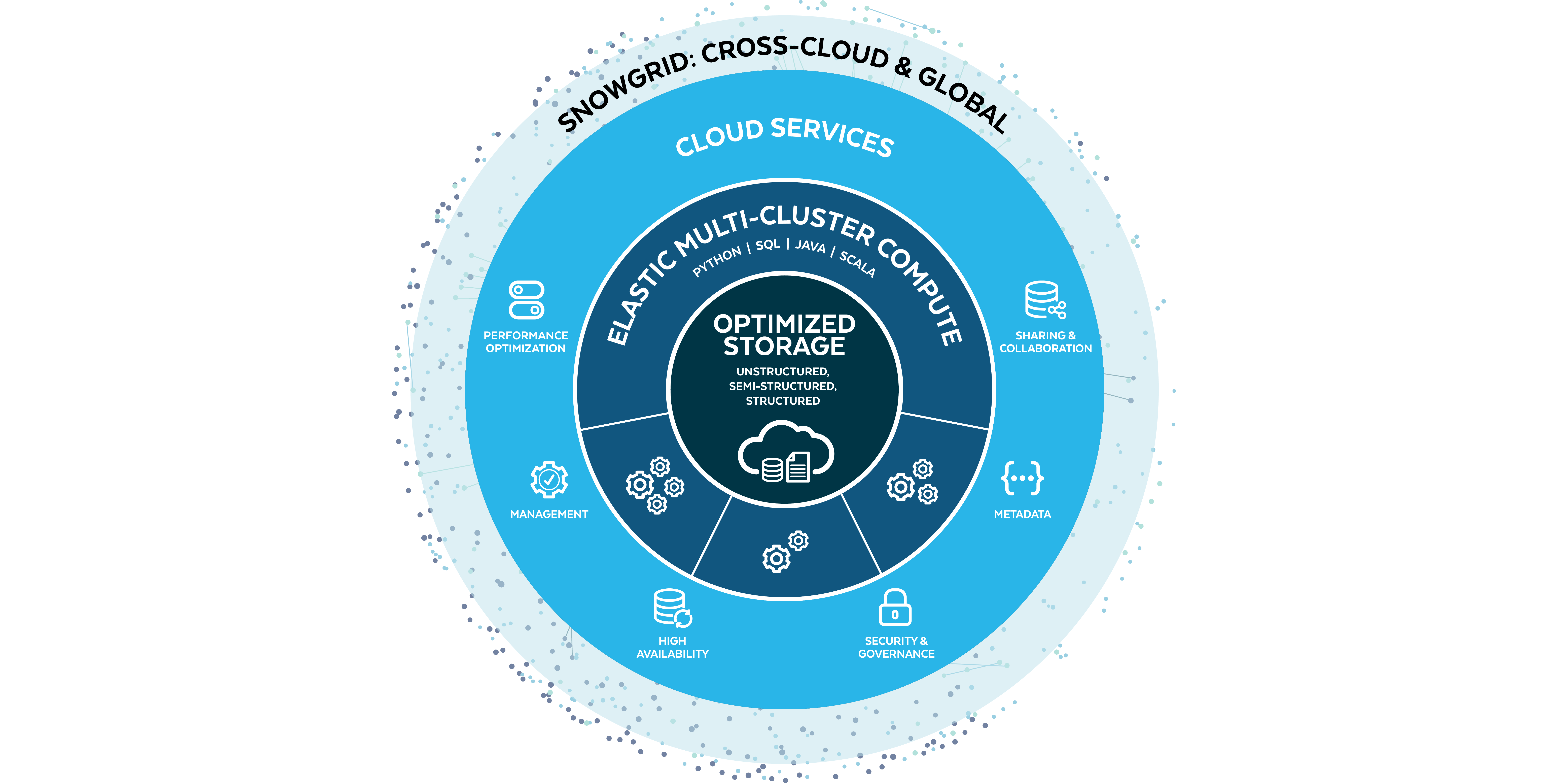
The Layers of
Snowflake's Platform
Optimized Storage
- Centralize unstructured, semi-structured, and structured data together for unsiloed access to all the data you need.
- Let Snowflake manage your data with optimized compression, automatic micro-partitioning, ACID compliance, Time Travel, and more.
- Deploy a range of architectural patterns, including data lakes, data warehouses, data meshes, and others, and even work with data that exists on-premises or in open table formats (in private preview).


Elastic Multi-Cluster Compute
- Power complex data pipelines, large-scale analytics, feature engineering, interactive applications, and more, all with one engine.
- Instantly and cost-efficiently scale to handle virtually any number of concurrent users and workloads, without impacting performance.
- Snowflake delivers flexible, extensible, and powerful ways to program with data– from robust SQL support to the Snowpark developer framework for Python, Java, and Scala.
Cloud Services
- Let Snowflake handle the heavy lifting. As a fully managed service, you get automations that reduce risk, improve efficiencies, and let your team focus on what matters.
- Snowflake is built for high availability and high reliability so you can stay up and running.
- Transparent improvements give you faster performance and help you expand to new use cases– no action required.


SNOWGRID
- Discover and share governed data between teams, business units, partners, customers, and more, all without ETL.
- Cross-cloud governance controls and flexible policies ensure data and collaboration is secure, so you can unlock more value from even sensitive and regulated data.
- Maintain new levels of business continuity with cross-cloud and cross-region replication and failover, so you can operate without disruption and deliver better customer experiences.
- Enrich your insights with third-party data, connect with thousands of Snowflake customers, and extend your workflows with data services and third-party functions all through the Snowflake Marketplace.
One Platform
Many Workloads
A single, global platform to power essential workloads and unlock seamless collaboration.

EXPLORE OTHER
WORKLOADS

Accelerate your workflow with near-unlimited access to data and data processing power.





ways to
get started



start your 30-day
free trial
Try Snowflake free for 30 days and experience the Data Cloud that helps eliminate the complexity, cost, and constraints inherent with other solutions. Available on all three major clouds, Snowflake supports a wide range of workloads, such as data warehousing, data lakes, and data science.