
Hopefully you had a chance to read our previous posts: Query Results Sets available in history, Ability to connect with JDBC, and Undrop a table, schema or a database. As promised in the original Top 10 post, we continue the series with a deeper dive into another of the Top 10 Cool Features from Snowflake:
#7 Fast Clone
Even cooler than UNDROP is our fast clone feature.
Have you ever had to wait hours, days, maybe weeks to spin up a copy of your production data warehouse so you could have a test or a development environment? And have to pay extra for the test or development environment to able to hold all the replicated data? Or maybe you have some new data scientists that just want to play around with the data but they really need their own copy?
With the simple Snowflake CLONE command, our customers can create multiple copies of the data tables, schemas, and databases, without replicating the data itself. This gives our customers the ability to almost instantly make the data available to use for multiple user groups, without the additional cost (or time) of actually replicating the data.
Magic??
Almost –
Magic with Meta Data.
Based on our unique solution, Snowflake users are able to clone their tables, schema or databases without creating additional copies. Snowflake stores data in files that are immutable, and encrypted, as part of our architecture. Our cloud services layer, with the metadata repository, records the information regarding the files being stored, the file locations, and a reference to a certain version of the data. This is also kept encrypted. In addition, when any data changes, the Metadata repository is automatically updated to provide a pointer to the changed data. All of this is performed in the background by the software without any involvement from the user. The metadata repository still retains the record for all versions of the data set.
How Cloning works
Because of the data in the metadata store, the user can quickly create a clone of the table. All the user has to do is to submit the clone command. This command can be submitted at any time.
CREATE OR REPLACE TABLE MyTable_V2 CLONE MyTable
As a result of the CLONE command, the system simply creates a new entry in the metadata store to keep track of the new clone.
Time Traveling Clones! Oh My!
In addition to simple cloning of objects, you can blend cloning with Snowflake time travel to clone tables, schemas, or even databases at a point in time in the past AT or BEFORE a specific timestamp. Here is an example:
CREATE SCHEMA mytestschema_clone_restore CLONE testschema BEFORE (TIMESTAMP => TO_TIMESTAMP(40*365*86400));
This command once executed will create a clone of the entire schema (tables, views, etc.) as it existed before the specified timestamp.
Hmm…time traveling clones…sounds like an episode of the X-Files (also cool).
Because Snowflake maintains the history of queries performed and identifies them by unique ID, we can also submit a request to create a clone using the unique ID of the query, BEFORE or AT a certain time stamp. This would allow you to perhaps run a revised set of scripts against an older data set then compare the results to the current data set.
In addition, once cloned, cloned objects are independent of each other. Despite being independent, there are no additional storage requirements and thus no additional charge (unless you add or modify records), since these clones share files. Thus Snowflake allows its customers to clone at multiple levels: table, schema (file format, views, sequences, stages) and databases and over time. And because they are independent, updates to one are not visible in the others.
Very helpful for experimentation and data exploration!
Cloning Example
As an example of what it looks like in the Snowflake UI, here is a snapshot of one of my demo databases with Twitter data. It is about 2 TB of data.

Now here is me launching the Clone via our Web UI at 3:02:49 PM:
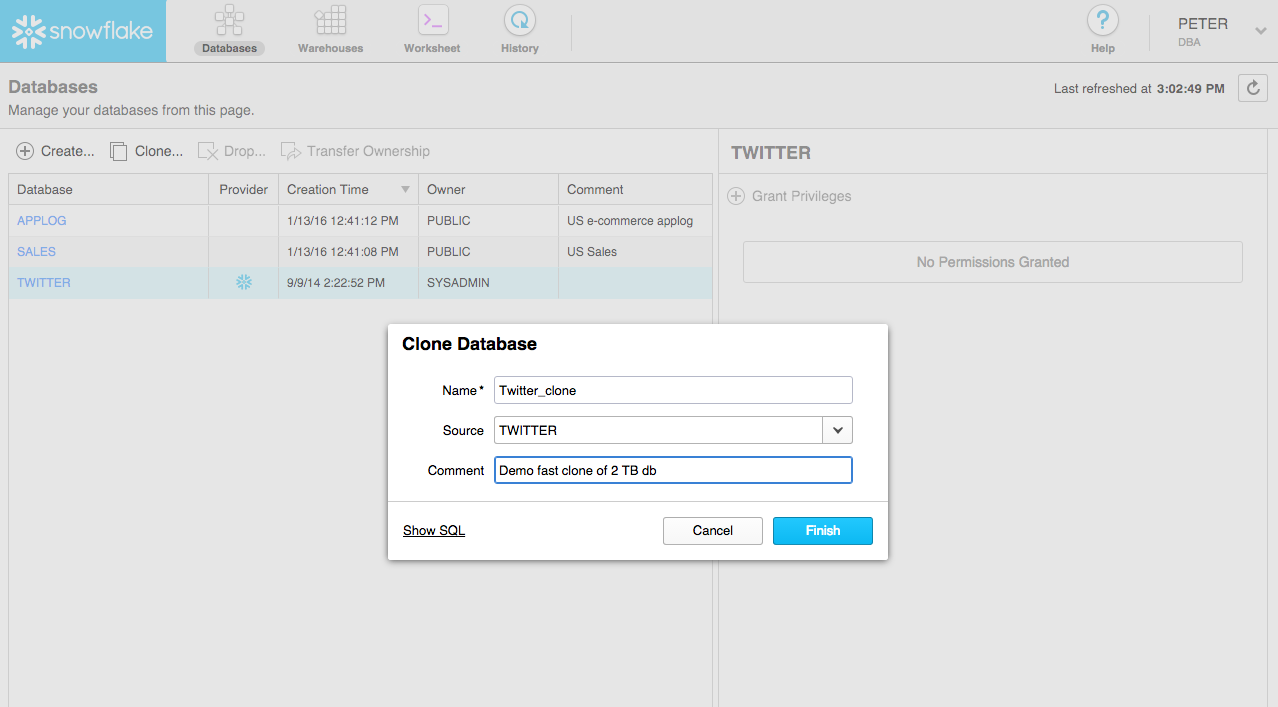
And here is the result showing the cloned db created at 3:03:55 PM. Barely a minute to create a clone of a 2TB database with 10 tables!
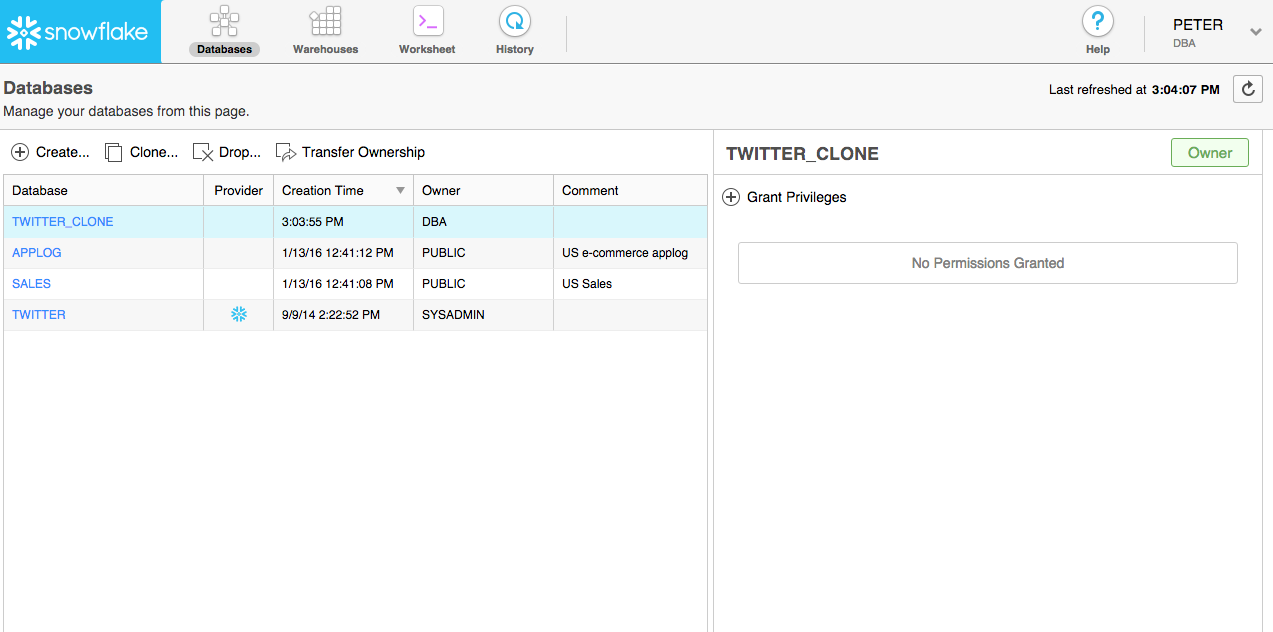
And I am not a DBA let alone a “cloud” DBA. This is all part of Snowflake being a Data Warehouse as a Service (DWaaS). Another reason why I think it is way cool!
Want to see cloning in action? Check out this video:
Why is this hard to do in traditional systems?
In traditional RDBMS systems, if you wanted to clone an existing data warehouse and give a different set of users access to the environment, you typically have to create a whole new, separate, deployment of the environment. In Snowflake, as I have just shown, you can do this with ease with just a few commands (one of the many benefits resulting from having written Snowflake from scratch for the cloud). Moreover, while most traditional data warehouse systems allow you to create snapshots of the data, this generally results in consumption of more storage (which of course costs more $$).
All these reasons are why Fast Cloning made my Top 10 list of really cool features in the Snowflake Elastic Data Warehouse.
As always, keep an eye on this blog site, our Snowflake Twitter feeds (@SnowflakeDB), (@kentgraziano), (@cloudsommelier), and #ElasticDW for more Top 10 Cool Things About Snowflake and for updates on all the action and activities here at Snowflake Computing.
Special thanks to Ashish Motivala from Snowflake Engineering for helping us with some of the more technical details on how this works so well.
Kent Graziano and Saqib Mustafa



