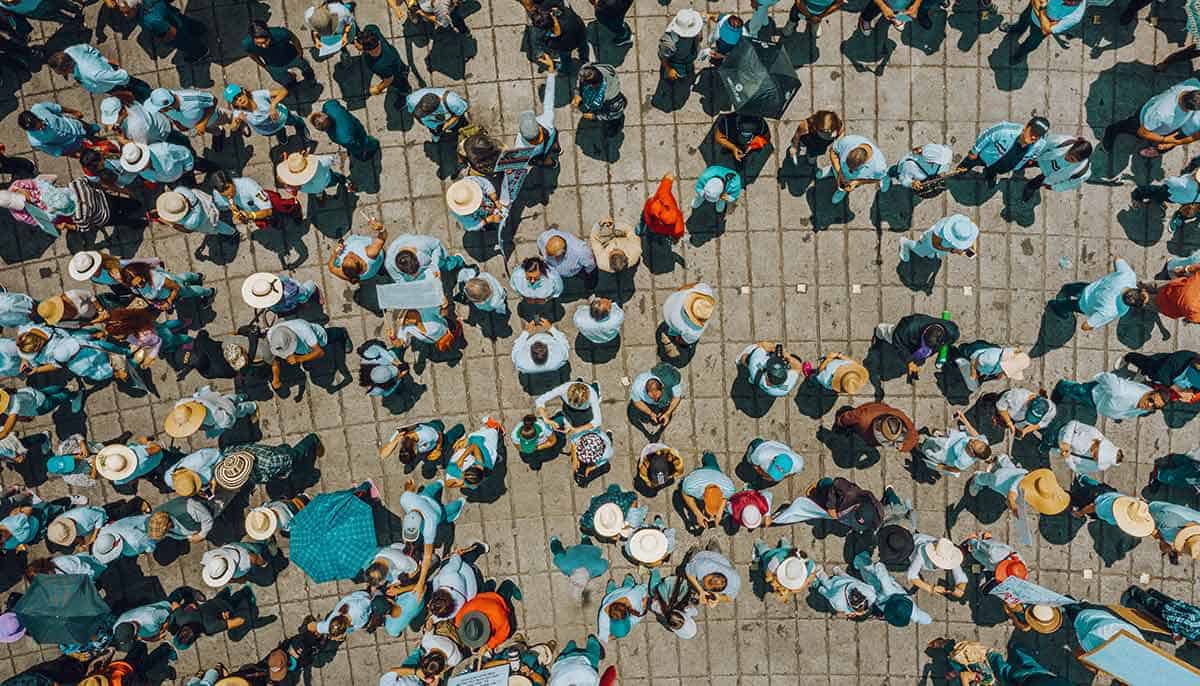In the first article of this series, I discussed the Snowflake data type VARIANT, showed a simple example of how to load a VARIANT column in a table with a JSON document, and then how easy it is to query data directly from that data type. In this post I will show you how to access an array of data within the JSON document and how we handle nested arrays. Then finally I will give you an example of doing an aggregation using data in the JSON structure and how simple it is to filter your query results by referring to values within an array.
Handling Arrays of Data
One of the features in JSON is the ability to specify and imbed an array of data within the docuement. In my example one such array is children:
"children": [
{ "name": "Jayden", "gender": "Male", "age": "10" },
{ "name": "Emma", "gender": "Female", "age": "8" },
{ "name": "Madelyn", "gender": "Female", "age": "6" }
]
You will notice there are effectively 3 rows in the array and each row has 3 sub-columns – name, gender, and age. Each of those rows constitutes the value of that array entry which includes all the sub-column labels and data (remember that for later). So how do you know how many rows there are if you do not have access to the raw data?
Like this:
select array_size(v:children) from json_demo;
The function array_size figures it out for us. To pull the data for each “row” in the array, we use the dot notation from before, but now with the added specification for the row number of the array (in the [] brackets):
select v:children[0].name from json_demo union all select v:children[1].name from json_demo union all select v:children[2].name from json_demo;

So this is interesting but then, I really do not want to write union all SQL to traverse the entire array (in which case I need to know how many values are in the array right?).
We solve that problem with another new extended SQL function called FLATTEN. FLATTEN takes an array and returns a row for each element in the array. With that you can select all the data in the array as though they were in table rows (so no need to figure out how many entries there are).
Instead of doing the set of UNION ALLs, we add the FLATTEN into the FROM clause and give it a table alias:
select f.value:name from json_demo, table(flatten(v:children)) f;
This syntax allows us to creating an inline virtual table in the FROM clause.
In the SELECT, we can then reference it like a table. Notice the notation f.value:name.
f = the alias for the virtual table from the children array
value = the contents of the element returned by the FLATTEN function
name = the label of the specific sub-column we want to extract from the value
The results, in this case, are the same as the SELECT with the UNIONs but the output column header reflects the different syntax (since I have not yet added any column aliases).

Now, if another element is added to the array (i.e., a 4th child), the SQL will not have to be changed. FLATTEN allows us to determine the structure and content of the array on-the-fly! This makes the SQL resilient to changes in the JSON document.
With this in hand, we can of course get all the array sub-columns and format them just like a relational table:
select f.value:name::string as child_name, f.value:gender::string as child_gender, f.value:age::string as child_age from json_demo, table(flatten(v:children)) f;
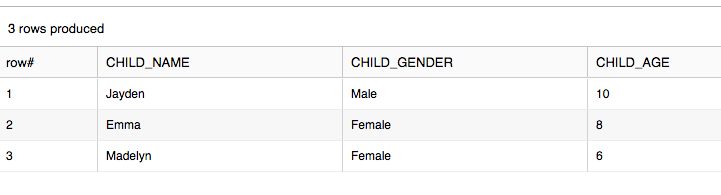
Putting this all together, I can write a query to get the parent’s name and all the children like this:
select v:fullName::string as parent_name, f.value:name::string as child_name, f.value:gender::string as child_gender, f.value:age::string as child_age from json_demo, table(flatten(v:children)) f;
Which results in this output:
If I just want a quick count of children by parent, I do not need FLATTEN but refer back to the array_size:
select v:fullName::string as Parent_Name, array_size(v:children) as Number_of_Children from json_demo;

Handling Multiple Arrays
You may recall there are multiple arrays in our sample JSON string. I can pull from several arrays at once with no problem:
select v:fullName::string as Parent_Name, array_size(v:citiesLived) as Cities_lived_in, array_size(v:children) as Number_of_Children from json_demo;

What about an Array within an Array?
Snowflake can handle that too. From our sample data we can see yearsLived is an array nested inside the array described by citiesLived:
"citiesLived": [
{ "cityName": "London",
"yearsLived": [ "1989", "1993", "1998", "2002" ]
},
{ "cityName": "San Francisco",
"yearsLived": [ "1990", "1993", "1998", "2008" ]
},
{ "cityName": "Portland",
"yearsLived<": [ "1993", "1998", "2003", "2005" ]
},
{ "cityName": "Austin",
"yearsLived": [ "1973", "1998", "2001", "2005" ]
}
]
To pull that data out, we add a second FLATTEN clause that transforms the yearsLived array within the FLATTENed citiesLived array.
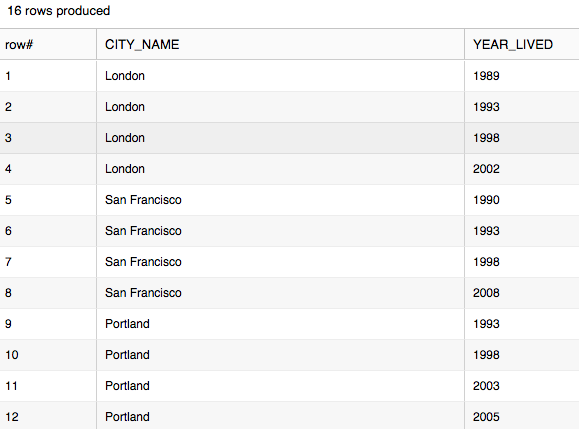
select tf.value:cityName::string as city_name, yl.value::string as year_lived from json_demo, table(flatten(v:citiesLived)) tf, table(flatten(tf.value:yearsLived)) yl;
In this case the 2nd FLATTEN (alias “yl”) is transforming (really pivoting) the yearsLived array for each value returned from the 1st FLATTEN of the citiesLived array (“tf”).
The results output shows Year Lived by City:
Like my earlier example, I can then augment this result by adding in the name too (so I know who lived where):
select v:fullName::string as parent_name, tf.value:cityName::string as city_name, yl.value::string as year_lived from json_demo, table(flatten(v:citiesLived)) tf, table(flatten(tf.value:yearsLived)) yl;
Aggregations?
Yup, we can even aggregate data within semi-structured data. (We would not be much of a data warehouse service if we couldn’t, right?)
So, just like ANSI SQL, we can do a count(*) and a group by:
select tf.value:cityName::string as city_name, count(*) as years_lived from json_demo, table(flatten(v:citiesLived)) tf, table(flatten(tf.value:yearsLived)) yl group by 1;
And the results:

Filtering?
Of course! Just add a WHERE clause.
select tf.value:cityName::string as city_name, count(*) as years_lived from json_demo, table(flatten(v:citiesLived)) tf, table(flatten(tf.value:yearsLived)) yl where city_name = 'Portland' group by 1;

To simplify things, notice I used the column alias city_name in the predicate but you can also use the full sub-column specification tf.value:cityName as well.
Schema-on-Read is a Reality
I could go on, but by now I think you can see we have made it very easy to load and extract information from semi-structured data using Snowflake. We added a brand new data type, VARIANT, that lives in a relational table structure in a relational database without the need to analyze the structure ahead of time, design appropriate database tables, and then shred the data into that predefined schema. Then I showed you some easy to learn extensions to ANSI-standard SQL for accessing that data in a very flexible and resilient manner.
With these features, Snowflake gives you the real ability to quickly and easily load semi-structured data into a relational data warehouse and make it available for immediate analysis.
To see this feature in action, check out this short video.
Be sure to keep an eye on this blog or follow us on Twitter (@snowflakedb and @kentgraziano) for all the news and happenings here at Snowflake.
P.S. If you don’t already have a Snowflake account, you can sign up for a self-service account here and get a jumpstart with $400 in free credits!