
Today’s organizations struggle to load, integrate and analyze the sources of streaming data they rely on to advance their businesses. The Internet-of-things, mobile devices, adtech scenarios, telemetry systems and application health monitoring are just some of the scenarios driving this trend. To remain competitive, organizations require this data to drive their analytics in near real time.
Despite the rapid rise in streaming data, and the infinite scalability of the cloud, traditional data warehousing solutions can’t deliver seamless ingestion for streaming data. They still require processes originally designed for batch loading, happening once or a few times per day. This unnecessary latency is a drag on an organization’s analytics. Workarounds using micro-batching provide some relief but are difficult to implement and require careful tuning. Equally, serverless computing is still foreign to most traditional data warehouse solutions. In fact, most cloud data warehouses, which are “cloud-washed” versions of on-premises solutions, do not offer a serverless experience.
Snowpipe tackles both continuous loading for streaming data and serverless computing for data loading into Snowflake. With Snowpipe, AWS S3 event notifications automatically trigger Snowflake to load data into target tables. Snowflake SQL queries retrieve the most recent data within a minute after it arrived to the S3 bucket.
The “pipe” is a key concept in the surface area that Snowpipe adds to Snowflake. A pipe definition wraps the familiar COPY statement for data loading with Snowflake. Most of the semantics from the existing COPY statement carry forward to a pipe in Snowpipe. The main difference, though, is that pipes are continuously watching for new data and are continuously loading data from the stage used by the pipe.
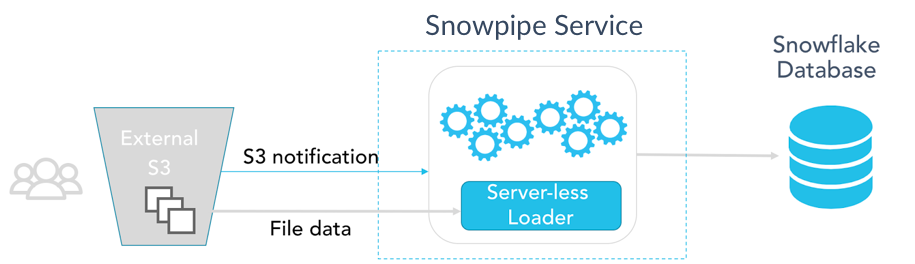
Snowpipe’s surface area provides two different levels of control for pipes. With most use cases, Snowpipe can rely on Amazon SQS notifications from an S3 bucket to trigger data loads. It requires a one-time configuration for an S3 bucket and a set of target tables. This usually takes less than 15 minutes to set up. It’s completely configuration-based, with no need to write any application code other than some Snowflake DDL statements. This experience is available for preview in December 2017. The following diagram illustrates this approach:
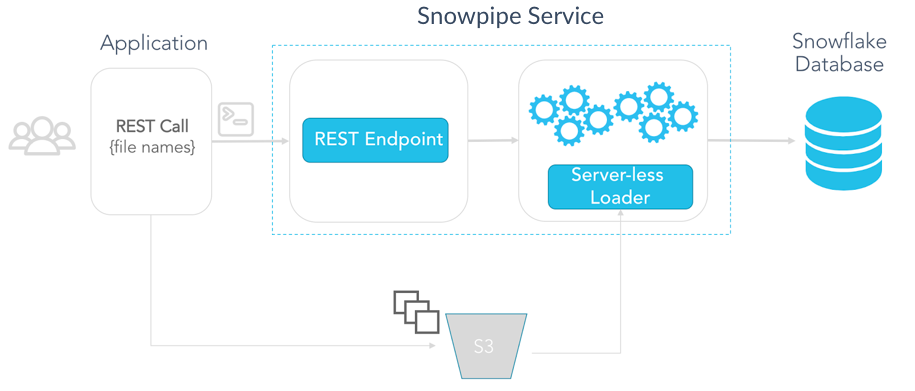
For use cases that require more control or deeper integration into applications, Snowpipe also provides a programmatic REST API to notify Snowflake of new data in S3. The REST API is available today in preview for Snowflake customers in the US West region. The following diagram shows an architectural overview of this approach:
For both Snowpipe experiences, Snowflake runs and manages a fleet of servers that asynchronously perform the actual data loading into the target tables. This server fleet is completely internal to Snowflake, which automatically adds or removes servers from the fleet depending on the current Snowpipe load. Customers don’t need to worry about monitoring or managing compute capacity when using Snowpipe for their data loads.
Snowpipe utilization, billing and cost
Snowpipe uses a serverless billing model. Customers are charged based on their actual compute resource utilization rather than capacity reservations that may be idle or overutilized. Instead, Snowpipe tracks the resource consumption of pipes in a given Snowflake account for the load requests that the pipe processed, with per-second/per-core granularity. The utilization recorded is then translated into familiar Snowflake credits. Snowpipe utilization shows up in the form of Snowflake credits on the bill, and account administrators can track Snowpipe utilization on their Snowflake account pages during the course of the month. Snowpipe utilization is shown as a special Snowflake warehouse – indicated by the Snowflake logo proceeding the warehouse name – in the Warehouse tab in Billing & Usage on the Snowflake web portal.
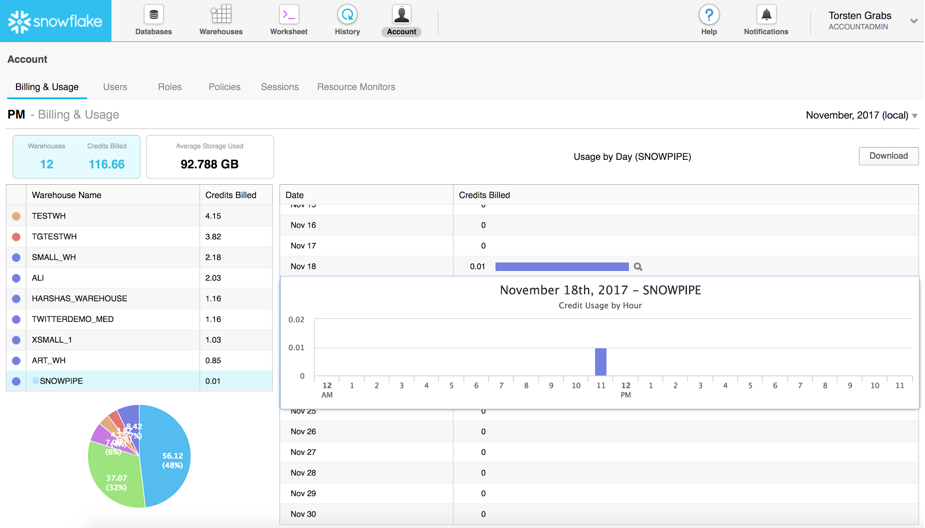
A table function called pipe_utilization_history in Snowflake SQL allows you to drill into Snowpipe utilization details over specific periods of time or for specific pipes.
Give Snowpipe a spin today and let us know your feedback. Snowpipe using REST-based notifications is available today. You can find the documentation and information on how to get started here.
Snowpipe with auto-ingest using SQS is available in December. If you are interested in participating in a private preview for this capability, please let us know here. Make sure to also read part two of this blog about Snowpipe here.
You can also try Snowflake for free. Sign up and receive $400 US dollars worth of free usage. You can create a sandbox or launch a production implementation from the same Snowflake environment.