WORKLOAD
Snowflake per il Data engineering
Crea potenti pipeline di dati in streaming o batch, in SQL o Python.




Semplifica i requisiti di data engineering
Crea pipeline di dati streaming o batch su un’unica piattaforma, con i vantaggi delle pipeline dichiarative e la convenienza dell’aggiornamento incrementale.
Elimina le pipeline non necessarie con il data sharing
Nel Marketplace Snowflake accedi a dati aggiornati e pronti all’uso direttamente da migliaia di data set e app, senza dover creare le pipeline.
Crea codice usando il linguaggio che preferisci in un unico motore ottimizzato
Programma in Python, SQL o molti altri linguaggi, poi esegui sfruttando la capacità di elaborazione multi-cluster di Snowflake, senza ricorrere a un’infrastruttura separata.
Come funziona
Esegui lo streaming dei dati con una latenza inferiore a 10 secondi
I sistemi streaming e batch, spesso separati, sono generalmente difficili da gestire e costosi da espandere. Ma Snowflake garantisce la massima semplicità, permettendo di gestire tutte le attività di ingestion e trasformazione dei dati, sia streaming che batch, in un singolo sistema.
Con Snowpipe Streaming trasmetti in streaming i set di righe in tempo quasi reale con una latenza inferiore ai 10 ms, o carichi automaticamente i file con Snowpipe. Entrambe le opzioni sono serverless, per ottimizzare scalabilità e convenienza.

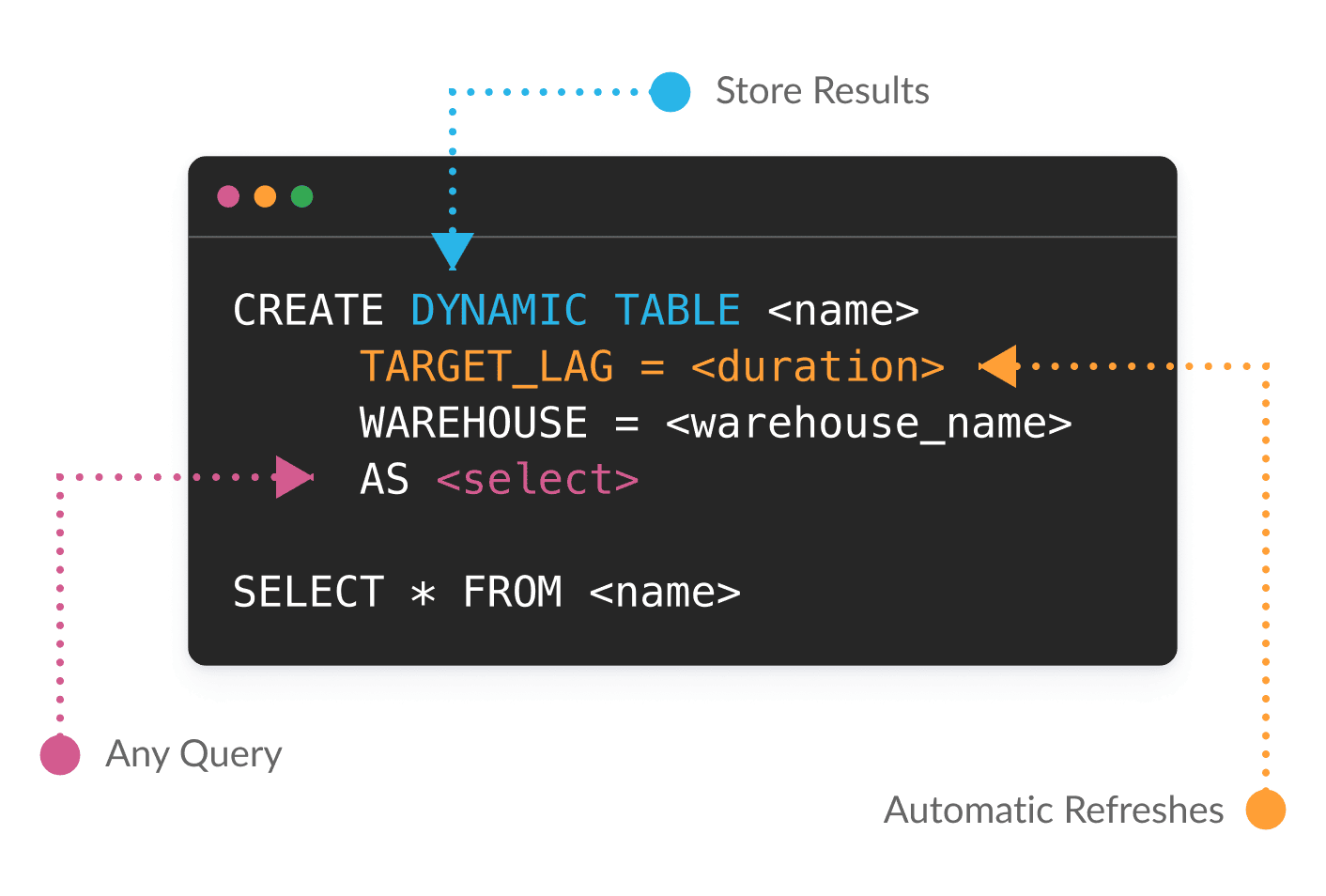
Regola la latenza modificando un singolo parametro
Con Dynamic Tables (in public preview), utilizzi SQL o Python per definire le trasformazioni dei dati in modo dichiarativo. Snowflake gestisce le dipendenze e genera automaticamente i risultati in base ai tuoi target di aggiornamento. Poiché le Dynamic Tables operano solo sui dati che hanno subito modifiche dopo l’ultimo aggiornamento, semplificano le pipeline complesse e ad alto volume di dati e i costi si riducono.
E quando le esigenze aziendali cambiano, basta modificare un singolo parametro di latenza per trasformare agevolmente una pipeline batch in una pipeline in streaming.
Potenzia il data engineering per l’analisi, l’AI, il ML e le applicazioni
Porta i workload dove sono i dati, per semplificare l’architettura della pipeline e fare a meno di un’infrastruttura separata.
Applicando il codice direttamente ai dati puoi rispondere a esigenze aziendali di ogni tipo, dall’accelerazione delle analisi alla creazione di app che sfruttano tutto il potenziale dall’AI generativa e dei LLM. In Snowpark puoi scegliere di utilizzare il tuo linguaggio preferito tra SQL, Python, Java e Scala.

Ottieni prestazioni 3,5 volte più veloci e risparmi sui costi del 34% senza compromettere la governance
Scrivi il codice in Python, Java o Scala, utilizzando il set di librerie di Snowpark, che include l’API DataFrame, e runtime come UDF e stored procedure. Successivamente, distribuisci ed elabori il codice in modo sicuro nella posizione di residenza dei dati, garantendo al tempo stesso una governance coerente in Snowflake.
Con Snowpark, i clienti registrano una mediana di performance 3,5 volte più veloci e costi inferiori del 34% rispetto alle soluzioni Spark gestite.1
Riduci il numero delle pipeline di dati con un data sharing semplice
Con il Data Cloud, hai a portata di mano una vastissima rete di dati e applicazioni.
L’accesso diretto ai data set aggiornati del Marketplace Snowflake semplifica la distribuzione di dati e applicazioni, permettendo di ridurre i costi e il carico di lavoro associato alle tradizionali pipeline ETL e alle integrazioni basate su API. In alternativa, puoi semplicemente utilizzare i connettori nativi per caricare i dati.
I NOSTRI CLIENTI
I leader utilizzano Snowflakeper il data engineering





Per iniziare
Tutte le risorse di data engineering che ti servono per creare pipeline con Snowflake.

Iniziare con Snowflake
Con i tutorial Snowflake per il data engineering inizi a operare in tempi brevissimi.

Hands-On Lab virtuale
Partecipa a un laboratorio pratico virtuale con istruttore e impara a creare le tue pipeline di dati con Snowflake.

Community Snowflake
Partecipa ai forum della community e agli User Groups Snowflake. Incontra una rete globale di professionisti dei dati e impara dalla loro esperienza.
Inizia la tua provagratuita di 30 giorni
Prova Snowflake gratis per 30 giorni e scopri come il Data Cloud aiuta a eliminare
la complessità, i costi e i vincoli tipici di altre soluzioni.
1Fonte dei dati: Risultati dei clienti Snowpark