
AWS upgraded its CloudHSM offering, rebranding the original service as AWS CloudHSM Classic. This blog post is about AWS CloudHSM Classic. We modified the blog post to reflect the name change.
Security of customer data is critically important at Snowflake, and so is availability of our service. In a previous blog post we described why AWS CloudHSM Classic is an importing building block of Snowflake’s database security infrastructure. In summary, CloudHSM Classic allows us to:
- Safely store Snowflake’s most important keys
- Execute important cryptographic operations on the device so that these keys never leave the HSM
- Generate strong random numbers when creating other encryption keys in Snowflake.
Strong security is only one promise we make to our customers; availability is another. To ensure Snowflake’s data warehouse service is always available, we use CloudHSM Classic in high-availability mode. In this blog post we will describe AWS CloudHSM Classic’s high-availability mode and our experiences with it.
AWS CloudHSM Classic’s High-Availability Mode
To make CloudHSM Classic highly available, Amazon recommends using two HSMs. Encryption keys are replicated on both HSMs, and cryptographic operations continue even if one HSM is unavailable. Of course this also means you pay for two HSMs, practically doubling the costs of using CloudHSM Classic. However, you get higher availability guarantees, which is crucial for a service like Snowflake’s data warehouse.
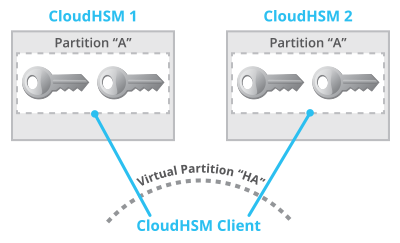
Once Amazon provisions two HSMs, setting up high availability is straightforward. Essentially both HSMs need to be populated with the same partitions to store keys (think of directories or buckets where keys are stored) and then each pair of partitions needs to be included in a “virtual partition” that spans both physical partitions. These virtual partitions exist only in the configuration file for the CloudHSM Classic client; the HSMs do not know about them. Figure 1 shows two HSMs in high-availability mode. Partition “A” exists on both HSMs, storing the same keys. A virtual partition “HA” spans both partitions. Only the client knows about both HSMs. The HSMs themselves do not know about each other, and do not communicate with each other.
Because the high-availability configuration is stored on the client, the client ensures replication and failover. The client interacts with both HSMs: storing keys, performing cryptographic operations, and generating random numbers. There is no interaction between HSMs.

In the case that one HSM is unreachable, failover is ensured by the client also. If accessing one HSM times out, the client will use its connection to the second HSM after about 10 seconds. In Figure 2, HSM 1 fails and the client connection to HSM 1 breaks. After a timeout, the client will fulfill the request by using its connection to HSM 2. Thus, the request to CloudHSM Classic will take longer, but it will succeed.
Backup HSM
One additional recommendation of Amazon is to “>have an offline backup HSM. In case of disaster, if both online HSMs are destroyed and lose all information, there is at least an offline backup of your stored keys. The offline HSM is not sold by Amazon directly, but by a third-party vendor. At Snowflake our keys are backed up using an offline HSM to be sure we never lose encryption keys.
Failover War Story
There is one scenario where failover of CloudHSM Classic does not succeed without additional intelligence in the application using CloudHSM. In this scenario, the CloudHSM client fails to retain connectivity even though at no point are both HSM instances down at the same time. We will first explain the scenario and then discuss how we have designed our application to ensure availability even in this scenario.
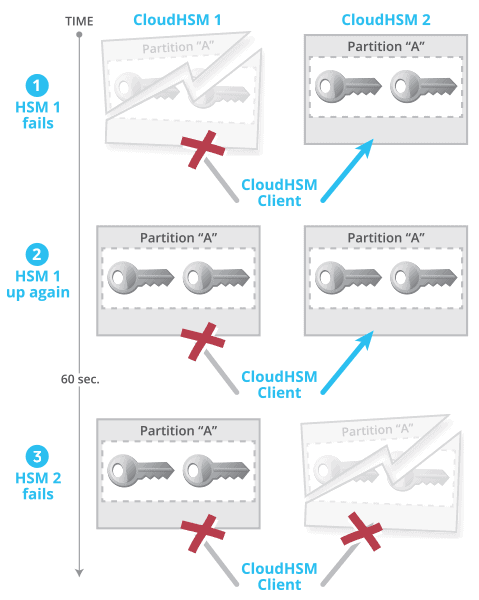
Figure 3: Scenario of unsuccessful HSM failover (AWS CloudHSM Classic)
The scenario, illustrated in Figure 3, consists of three successive steps:
- HSM 1 fails. The client’s connection to HSM 1 breaks but it successfully fails over to HSM 2.
- HSM 1 comes back up. CloudHSM client remains only connected to HSM 2.
- HSM 2 fails within 60 seconds of HSM 1 coming back up while there were no requests made to the HSM within these 60 seconds. The client’s connection to HSM 2 breaks as well. As a result, the client is not connected to any HSMs anymore.
Any subsequent requests from the client to the HSMs will fail, even though HSM 1 is up and running, and at no time were both HSMs unavailable at the same time. What happened is that the client never discovered that HSM 1 became available again. The client would only discover HSM 1 if there were requests sent to the HSMs in between steps 2 and 3, or if HSM 2 failed more than 60 seconds after HSM 1 became available again. (Note: this requires that auto-reconnect is enabled.) This scenario of an unsuccessful failover has been confirmed with Safenet, the technology provider for AWS CloudHSM Classic.
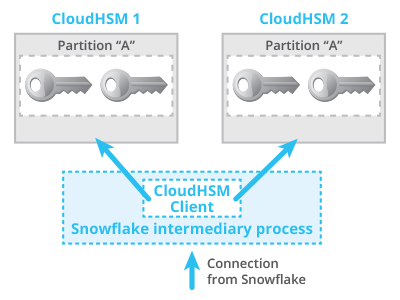
Snowflake’s workaround is two-fold:
- We use an intermediary process in between our service and CloudHSM that reconnects to AWS CloudHSM Classic in case of any exceptions (Figure 4)
- We restart this intermediary process periodically to ensure connectivity to both HSMs.
In the scenario above, the intermediary process receives an exception when issuing a request to CloudHSM after step 3 because no HSMs appear to be available. The intermediary process will restart internally, thus reconnecting to both HSMs and fulfilling the request successfully. The intermediary is restarted periodically to reconnect to both HSMs.
This additional safety measure guarantees availability of CloudHSM services, and therefore improves availability of the Snowflake data warehouse as a whole.



